Projects
2015 – 2016
ChatGrape
Kommunikationsplattform zur Vernetzung von Wissen und Workflows in Unternehmen
In the project, an approach was developed and implemented to classify chat messages into dialogue acts, focusing on questions and directives (“to-dos”). Our multi-lingual system uses word lexica, a specialized tokenizer and rule-based shallow syntactic analysis to compute relevant features, and then trains statistical models (support vector machines, random forests, etc.) for dialogue act prediction. The classification scores we achieve are very satisfactory on question detection and promising on to-do detection, on English and German data collections.
2013 – 2016
Automatic Segmentation, Labelling, and Characterisation of Audio Streams
The goal of this project is to develop technologies for the automatic segmentation and interpretation of audio files and audio streams deriving from different media worlds: music repositories, (Web and terrestrial) radio streams, TV broadcasts, etc. A specific focus is on streams in which music plays an important role.
2012 – 2016
INSYNC
Synchronization and Communication in Music Ensembles
Interpersonal communication and the coordination and synchronization of actions are fundamental human capacities. People use these functions routinely in activities such as shaking hands, driving a car, playing sports, or playing music as part of an ensemble. To coordinate your actions with someone else’s, you must be able to predict how the other person is going to behave. Music ensemble performance provides a particularly interesting context for studying prediction and coordination because the synchronization between actions must be so precise. Since music is dynamic, or time-varying, ensemble musicians must make predictions about their co-performers’ behaviour as they play, relying primarily on nonverbal cues provided by their co-performers’ body movements, breathing, and sound. This research project investigates the mechanisms underlying musical synchronization in small ensembles, using a combination of perceptual/performance experiments and computational modelling techniques.
2013 – 2016
Lrn2Cre8
Learning to Create
Lrn2Cre8 aims to understand the relationship between learning and creativity by means of practical engineering, theoretical study, and cognitive comparison. We begin from the position that creativity is a function of memory, that generates new structures based on memorised ones, by processes which are essentially statistical.
2013 – 2016
PHENICX
Performances as Highly Enriched aNd Interactive Concert eXperiences
Modern digital multimedia and internet technology have radically changed the ways people find entertainment and discover new interests online, seemingly without any physical or social barriers. Such new access paradigms are in sharp contrast with the traditional means of entertainment. An illustrative example of this is live music concert performances that are largely being attended by dedicated audiences only. The PHENICX project aims at bridging the gap between the online and offline entertainment worlds. It will make use of the state-of-the-art digital multimedia and internet technology to make the traditional concert experiences rich and universally accessible: concerts will become multimodal, multi-perspective and multilayer digital artefacts that can be easily explored, customized, personalized, (re)enjoyed and shared among the users.
2014 – 2015
ACCIA
Automated Coding and Categorizing of Innovation Areas
Generelles Ziel des Projekts „Automated Coding and Categorizing of Innovation Areas“ (ACCIA) war es, ein intelligentes automatisiertes System zu schaffen, das Belegstellen für problembezogene, innovationsrelevante Äußerungen, welche aus unterschiedlichen Online-Quellen extrahiert wurden, identifizieren, analysieren und kategorisieren kann. Durch die Einbindung von Verfahren aus den Bereichen Textverarbeitung, Document Clustering und Document Classification konnte ein Prozessmodell erarbeitet werden, dass eine bisher rein manuell durchgeführte Innovationsfeldanalyse in ein automatisiertes Modell überführt, in dem die manuelle, expertinnengetriebene Analyse mit automatischen, computerlinguistisch gestützten Verfahren verschränkt wird.
2014 – 2015
PotenziAAL
Potential and Limits of Present-day Robotics in Ambient Assisted Living
The central aim of the study is the realistic presentation of the potential of AAL Robotics, based on the analysis of parameters drawn from user needs, technical readiness, and existing business models. Instead of compiling yet another collection of individual solutions and projects, the PotenziAAL Study will aggregate existing knowledge gained from analysis of secondary sources with knowledge generated from primary sources such as expert interviews, a workshop and user focus groups in order to achieve a comprehensive picture of the state of the art in AAL Robotics and its future potential. The study will develop categories and criteria in order to foster exact characterization, comparability and quality assurance in AAL Robotics.
2014 – 2015
Cognitive-emotive Robotics for Supporting Autobiographic Storytelling
The aim of the project is the development of a virtual agent that interactively supports older persons in the narration of autobiographic stories, from listener feedback to raw transcription.
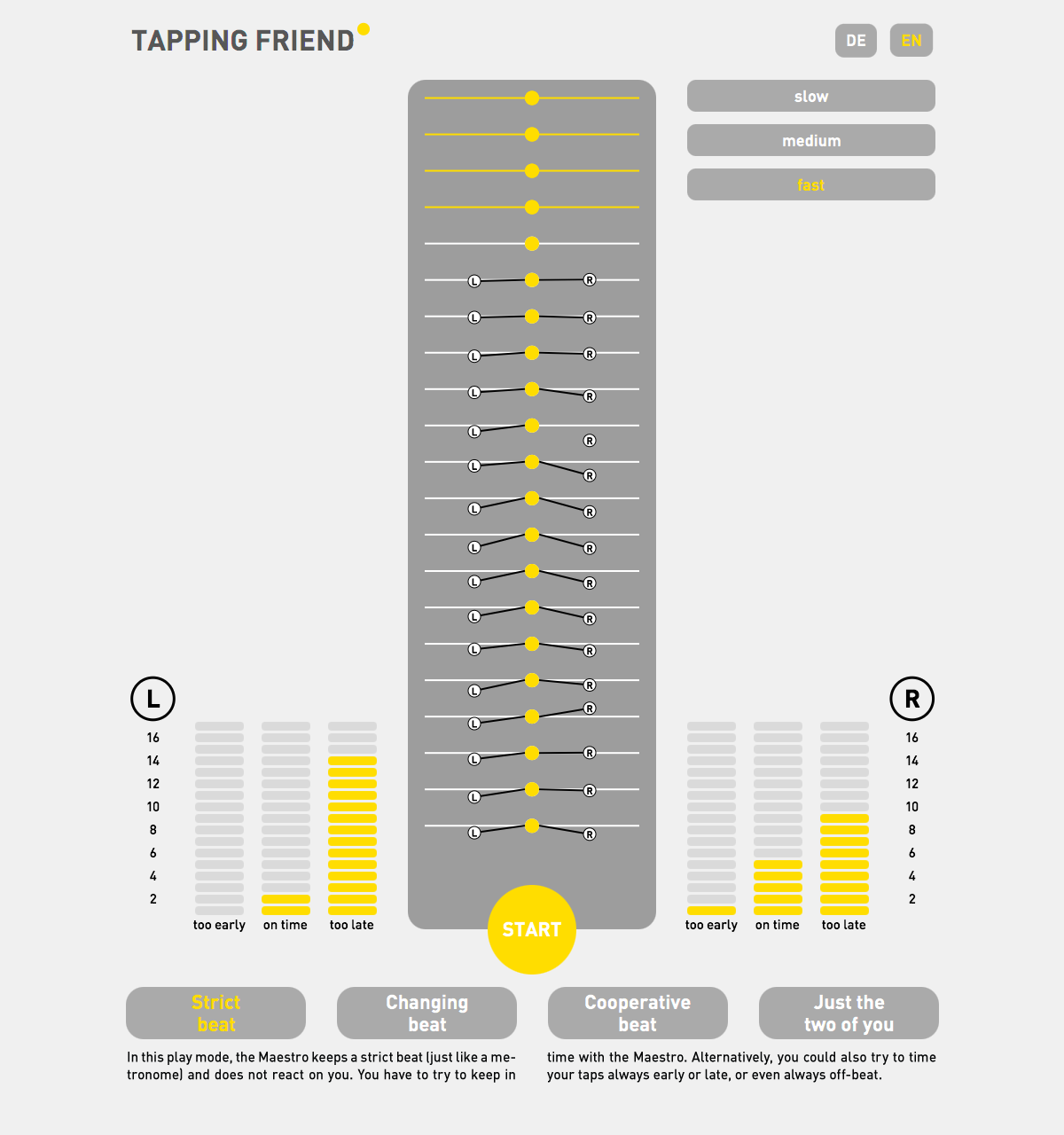
2015
Tapping Friend
An interactive exhibit on synchronization and cooperation between humans and a virtual partner
TAPPING FRIEND is an interactive science game for everyone between 6 and 99 years and is aimed to provide a playful experience of synchronization and cooperation between one or two humans and a virtual partner – the maestro. The players tap in time with the maestro on little drums and the system provides immediate feedback on their synchronization success by showing their taps relative to the maestro’s taps and by counting the taps that were on time and the taps that were too early or too late. The aim of the game is to achieve as many on-time taps as possible.