Projects

2019 – 2022
CoBot Studio
Crossing Realities for Mutual Understanding in Human–Robot Teams
The project researches human-robot interaction from a collaborative point of view where the mutual ability of human and robot to understand each other’s signals is core to the successful completion of joint tasks, and also plays a major role for human acceptance of and trust in the robot as a workmate. We study close collaborations of humans with cobots employing both Virtual Reality scenarios and real world encounters with a collaborative robot in industry-relevant scenarios.

2021-09 – 2022-02
STADIEM/Aiconix
The main target of STADIEM/Aiconix is to foster language technology for dialects and regional varieties. Using the AI-based platform provided by Aiconix, clients will be able to access and interact with huge amounts of digital media content, whereas the principal aim of this project is to significantly enhance ASR with respect to speech data from regional standards and dialects. In this 'develop phase' we primarily focus on Austrian varieties while foreseeing to scale up the methods upon other varieties of German and other languages.
2018 – 2021
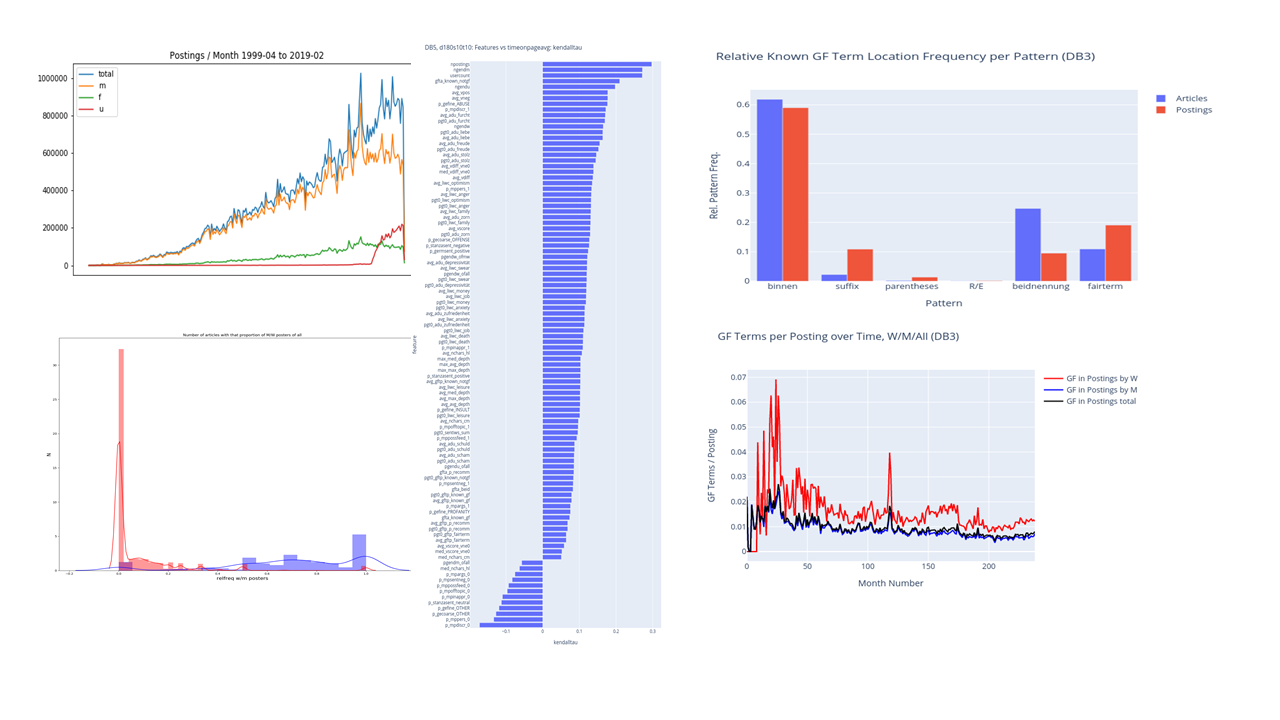
FemDwell
User-Centric Analysis & Improvement of Web Page Engagement with User Generated Content
The project analyses the time users spend on web pages of derStandard.at and how this relates to what people say and how the tone is in forum postings. A major aim is to investigate whether and how various linguistic and semantic aspects of the user-generated content influence the time users spend in a forum as readers and what motivates users to become active posters. A particular focus lies on female posters. While the percentage of female and male readers of derStandard.at is near equal (45% to 55%), there is a large gender mismatch in active posters, i.e., only 20% of those who write in forums are female). Therefore, important goals for the project are to find out reasons for this gender disparity and to take measures to encourage female contributions. Methods of data science and natural language processing are employed to identify correlations between forum dwell time, and linguistic and semantic properties of forum contributions, including gender-fair language use. Deep learning approaches are applied to identify mysogynic content. All this helps forum moderators to counteract female discrimination in the web.
2016 – 2021
Con Espressione
Towards Expressivity-aware Computer Systems in Music
The ERC project Con Espressione is about developing machines that are aware of certain dimensions of expressivity, specifically in the domain of (classical) music, where expressivity is both essential and - at least as far as it relates to the act of performance - can be traced back to well-defined and measurable parametric dimensions (such as timing, dynamics, articulation). The project aims at developing systems that can recognise, characterise, generate, modify, and react to expressive qualities in music.
2019 – 2021
MAIA.TOOLS
Medical artificial intelligence assistance tools
The project supports automatic analysis of conversations between doctors and patients such as explanations about treatments, surgeries, or aftercare. It combines Automatic Speech recognition (ASR) with Natural Language Processing (NLP). A system is developed that records doctor-patient conversation, analyzes and assesses what has been said contextually and semantically, and transfers this information into written documentation.

2019 – 2021
Human Tutoring of Robots in Industry
As the sensor systems of industrial robots continuously improve, more and more companies take the step towards cobots (collaborative robots) and integrate human-robot collaboration in their manufacturing processes. In the project Human Tutoring of Robots in Industry, we investigate requirements from industrial companies and research pathways to transfer insights from basic research on self-learning robots to industrial application. We pursue this endeavour based on an implemented model integrated into a robot that learns new actions and objects through observing and listening to their human tutor, conduct interviews and an online survey with stakeholders from industry.
2019 – 2021
Computational Pun-derstanding
Computer-assisted translation of humorous wordplay
The translation of wordplay is one of the most extensively researched problems in translation studies, but until now it has attracted little attention in the fields of artificial intelligence and language technology. In Computational Pun-derstanding, we study how professional translators process wordplay, with particular attention to the tools, knowledge sources, and working processes they employ. We then decompose these processes and look for parts that can be modelled computationally as part of an interactive, computer-assisted translation system. With this “machine-in-the-loop” paradigm, language technology is applied only to those subtasks it can perform best, such as searching a large vocabulary space for translation candidates matching certain phonetic and semantic constraints. Subtasks that depend heavily on real-world background knowledge—such as selecting the candidate that best fits the wider humorous context—are left to the human translator.
2015 – 2020
Proteinspace
Evolution and Function of the Environmental Protein Sequence Universe
Protein sequences are generated in large quantities by DNA sequencing and represent one of the most important reservoirs of molecular biological data. Protein sequences point to the molecular functions and biological roles of their gene products through blueprints of the function and structure of their encoded proteins and their connected evolutionary relationships. During the last decade, the sequencing of metagenomes directly from environmental samples without cultivation has significantly expanded the known protein sequence universe. However, the environmental protein universe is still mainly unstructured and awaits specific utilization in computational biology; although, hundreds of metagenomes have been deeply sequenced and thereby account for the majority of protein sequences stored in databases. The central aim of this proposal is investigating the fundamental evolutionary structures behind the environmental protein sequences previously obtained. We will cluster the entire protein sequence universe, including metagenomes, into evolutionary related families. Based on established concepts, such as orthology or protein domains, this project will develop novel clustering methods for large protein networks.
2019 – 2022
VALMIR
On Valid and Reliable Experiments in Music Information Retrieval
Music Information Retrieval (MIR), as the interdisciplinary science of retrieving information from music, conducts experiments with a multitude of methods from machine learning, statistics, signal processing, artificial intelligence, etc. It relies on the proper evaluation of all these methods to measure the success of new algorithms, or, in more general terms, chart the progress of the whole field of MIR. The principal role of computer experiments and their statistical evaluation within MIR is now widely accepted and understood, but the more fundamental notions of validity and reliability in MIR experiments are still rarely discussed within the field. This lack of awareness for valid and reliable MIR experimentation is at the heart of a number of seemingly puzzling phenomena in recent MIR research and will be tackled in this project. The project is currently located at the Johannes Kepler Universität Linz.
2019 – 2022
Dust and Data
The Art of Curating in the Age of Artificial Intelligence
Artificial intelligence and machine learning are both a challenge and a chance for today’s museums and their growing digital collections. „Dust and Data – The Art of Curating in the Age of Artificial Intelligence” (DAD) as a 2-years artistic research project strives to explore the curatorial potential of artificial intelligence within a set of co-operations with several museum institutions. DAD is located at the Academy of Fine Arts, Vienna and the Institute of Computational Perception, Johannes Kepler Universität Linz. During the first nine month, DAD was also located at the Austrian Research Institute for Artificial Intelligence (OFAI). DAD is funded by the FWF PEEK-program.