Projects
2016 – 2019
CoCreate
Coordination and Collaborative Creativity in Music Ensembles
Music ensemble performance requires precise temporal coordination between performers. As an art form, it also requires the creative interpretation of existing music, if not the creation of new music altogether. Thus, though ensemble musicians aim to sound unique, they are simultaneously constrained by the need to remain predictable to each other. How ensembles achieve well-coordinated performances in musical contexts requiring creative interpretation or improvisation is the question driving this research. Our aim is to identify the cognitive mechanisms underlying musical creativity in groups. We consider both human-human and human-computer collaboration to test how factors normally present in live human interaction (e.g. opportunity for communication, perception of co-performers as intention and responsive) affect creative collaboration.
2015 – 2019
SALSA
Semantic Annotation by Learned Structured and Adaptive Signal Representations
The goal of SALSA is to bridge the semantic gap in music information research (MIR) by using adaptive and structured signal representations. The semantic gap is the difference in information content between signal representations or models used in MIR and high-level semantic descriptions used by musicians and audiences. Examples are the mapping from signal representation to concrete content such as instrumentation or to more abstract tags such as the emotional experience of music.

2016 – 2019
RALLI
Robotic Action-Language Learning through Interaction
Future social robots will need the ability to acquire new tasks and behaviours on the job both through observation and through natural language instruction, for robot designers cannot build in all environmental and task contingencies. In this project, we tackle the critical subproblem of learning new actions and their corresponding words by the artificial system observing how those actions are performed and expressed by humans. Inspired from psychological studies, we develop experimentation-based algorithms for word learning, integrated with natural language understanding and generation.
2015 – 2019
Updatemi
Automatische Aggregation, Kontextualisierung, Zusammenfassung und Reformulierung von Nachrichten und Meldungen
Das Projekt beschäftigte sich mit der Zusammenfassung von News-Artikeln für News-Aggregatoren. Dabei wurden Lösungen für extraktive und abstraktive Summarization basierend auf Heuristiken und unter Anwendung maschinellen Lernens auf ihre Eignung für den konkreten Anwendungsfall untersucht. Entsprechende Funktionalitäten wurden in einem Prototyp implementiert. Im letzten Drittel des Projektes wurden in einer Pilotphase Ergebnisse aus dem Bereich News-Summarization auf die Rechtsdomäne übertragen und adaptiert.
2015 – 2018
CHARMING
Character Mining and Generation
The hero, the villain, the servant, the mentor, and many more ... movie and drama continue to rely on a repertoire of archetypical characters. But what makes a character? The proposed project CHARMinG will develop and apply AI methods from text and sentiment mining, natural language processing and machine learning to identify, from electronic sources of fictional dialogues (movie scripts, transcripts, drama texts), a set of indicators that convey the core of the relational/functional features and personality of characters, thereby leading to the generation of more colourful and engaging virtual characters.
2017 – 2018
De-escalation Bot
AI for a better discourse in online news fora
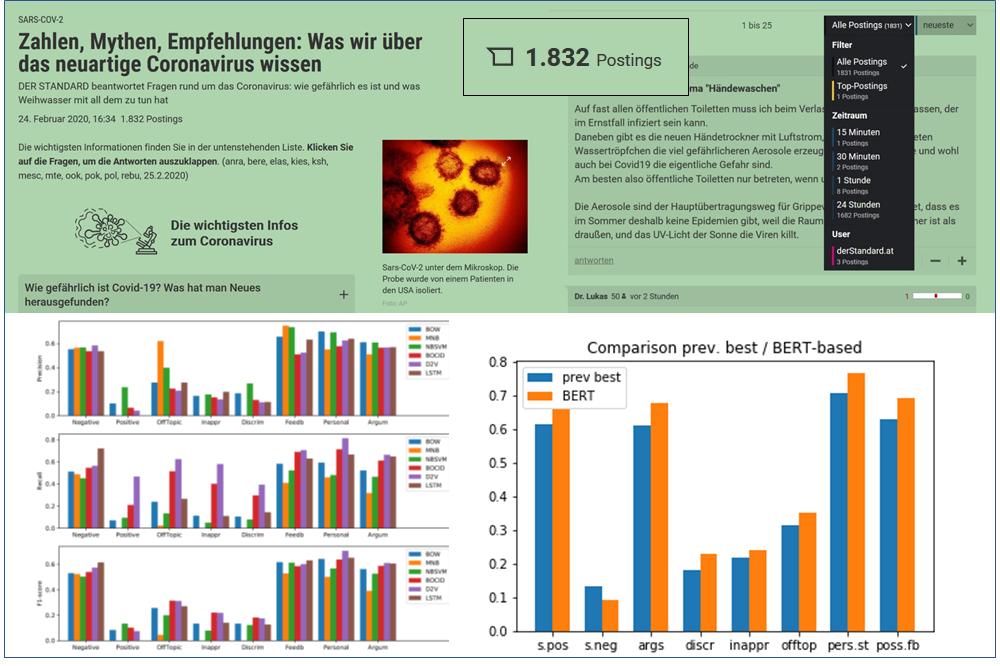
OFAI together with the Austrian (online) newspaper Der Standard developed the De-Escalation Bot, a series of machine learning based classifiers which scan forum postings for ones which are expected to provide valuable contributions to a forum and therefore should be visible not only for a rather short period of time but should be accessible to all users in a forum. The classifiers help forum moderators to identify such postings from a plethora of posts being produced by the forum users. Pinning respective posts on top of the forum has shown to improve the discussion quality, reports Der Standard (article in German).
2017 – 2018
aMOBY
Acoustic Monitoring of Biodiversity
The aMOBY project will use results from mathematical harmonic analysis combined with machine learning to acoustically monitor biodiversity. Biodiversity refers to the variety and variability of life on Earth, a diversity that is severely endangered due to human-made threats like habitat destruction, introduction of invasive species, over-population and over-harvesting, and of course climate change resulting from pollution of the atmosphere. Biodiversity monitoring is the repeated observation or measurement of biological diversity to diagnose and quantify its status and changes. A great challenge for monitoring of biodiversity lies in the sheer amount of data which clearly requires a high degree of automation to work on a grand scale.
2014 – 2018
On High Dimensional Data Analysis in Music Information Retrieval
Learning in high dimensional spaces poses a number of challenges which are referred to as the curse of dimensionality. Music Information Retrieval (MIR), as the interdisciplinary science of retrieving information from music, is very often relying on high dimensional feature representations and models. Hub songs are, according to the music similarity function, similar to very many other songs and as a consequence appear in very many recommendation lists preventing other songs from being recommended at all. It is due to the property of distance concentration which causes all points in a high dimensional data space to be at almost the same distance to each other. This proposed project will explore existing and develop new approaches to deal with these problems by studying their effects on a wide range of methods in MIR, but also multimedia and machine learning. In particular we are planning to (i) study and unify rescaling methods to avoid distance concentration, (ii) explore the role of hubness in unsupervised (clustering, visualization) and supervised learning (classification) in high dimensional spaces.

2015 – 2018
ATLANTIS
Artificial Language Understanding in Robots
ATLANTIS attempts to understand and model the very first stages in grounded language learning, as we see in children until the age of three: how pointing or other symbolic gestures emerge from the ontogenetic ritualization of instrumental actions, how words are learned very fast in contextualized language games, and how the first grammatical constructions emerge from concrete sentences. This requires a global, computational theory of symbolic development that informs us about what forces motivate language development, what strategies are exploited in learner and caregiver interactions to come up with more complex compositional meanings, how new grammatical structures and novel interaction patterns and formed, and how the multitude of developmental pathways observed in humans lead to a full system of multi-modal communication skills. This ambitious aim is feasible because there have been very significant advances in humanoid robotics and in the development of sensory-motor competence recently, and the time is ripe to push all this to a higher level of symbolic intelligence, going beyond simple sensory-motor loops or pattern-based intelligence towards grounded semantics, and incremental, long-term, autonomous language learning.
2013 – 2017
LIDA
Spatial Memory and Navigation Ability in a Physically Embodied Cognitive Architecture
The aim of this project is the development of a computational cognitive model of spatial memory and navigation based on the LIDA (Learning Intelligent Distribution Agent) cognitive architecture, integrated with the other high-level cognitive processes accounted for by LIDA, and physically embodied on a humanoid PR2 robot with the aid of the CRAM (Cognitive Robot Abstract Machine) control system. The LIDA cognitive architecture will be extended by a conceptual and computational, hierarchical spatial memory model, inspired by the neural basis of spatial cognition in brains.