Automatic Segmentation, Labelling, and Characterisation of Audio Streams
The goal of this project is to develop technologies for the automatic segmentation and interpretation of audio files and audio streams deriving from different media worlds: music repositories, (Web and terrestrial) radio streams, TV broadcasts, etc. A specific focus is on streams in which music plays an important role.
Specifically, the technologies to be developed should address the following tasks:
- automatic segmentation (with or without meta-information) of audio streams into coherent or otherwise meaningful units or segments (based on general sound or rhythm similarity or homogeneity, on specific types of content and characteristics, on repeated occurrences of subsections, etc.);
- the automatic categorisation of such audio segments into classes, and the association of segments and classes with meta-data derived from various sources (including the Web);
- the automatic characterisation of audio segments and sound objects in terms of concepts intuitively understandable to humans.
To this end, we plan to develop and/or improve and optimise computational methods that analyse audio streams, identify specific kinds of audio content (e.g., music, singing, speech, applause, commercials, ...), detect boundaries and transitions between songs, and classify musical and other segments into appropriate categories; that combine information from various sources (the audio signal itself, databases, the Internet) in order to refine the segmentation and gain meta-information; that automatically discover and optimise audio features that improve segmentation and classification; and that learn to derive comprehensible descriptions of audio contents from such audio features (via machine learning).
The research is motivated by a large class of challenging applications in the media world that require efficient and robust audio segmentation and classification. Application scenarios include audio streaming services and Web stream analysis, automatic media monitoring, content- and descriptor-based search in large multimedia (audio) databases, and artistic applications.
Publications
- Thomas Grill and Jan Schlüter: Two Convolutional Neural Networks for Bird Detection in Audio Signals. In Proceedings of the 25th European Signal Processing Conference (EUSIPCO 2017), Kos Island, Greece, 2017.
- Reinhard Sonnleitner and Gerhard Widmer: Robust Quad-based Audio Fingerprinting. In IEEE/ACM Transactions on Audio, Speech and Language Processing, Volume 24 (3), pp.409-421, 2016.
- Reinhard Sonnleitner, Andreas Arzt and Gerhard Widmer: Landmark-based Audio Fingerprinting for DJ Mix Monitoring. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR 2016), New York, USA, 2016.
- Jan Schlüter: Learning to Pinpoint Singing Voice from Weakly Labeled Examples. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR 2016), New York, USA, 2016. Best oral presentation award.
- Arthur Flexer and Thomas Grill: The Problem of Limited Inter-rater Agreement in Modelling Music Similarity. In Journal of New Music Research, Vol. 45, No. 3, pp. 239-251, 2016.
- Jan Schlüter and Thomas Grill: Exploring Data Augmentation for Improved Singing Voice Detection with Neural Networks. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, 2015.
- Thomas Grill and Jan Schlüter: Music Boundary Detection Using Neural Networks on Combined Features and Two-Level Annotations. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, 2015.
- Bernhard Lehner and Gerhard Widmer: Monaural Blind Source Separation in the Context of Vocal Detection. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, 2015.
- Christian Dittmar, Bernhard Lehner, Thomas Prätzlich, Meinard Müller, and Gerhard Widmer: Cross-version Singing Voice Detection in Classical Opera Recordings. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, 2015.
- Hamid Eghbal-zadeh, Bernhard Lehner, Markus Schedl, and Gerhard Widmer: I-Vectors for Timbre-based Music Similarity and Music Artist Classification. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR 2015), Malaga, Spain, 2015.
- Bernhard Lehner, Gerhard Widmer, and Reinhard Sonnleitner: Improving Voice Activity Detection in Movies. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH 2015), Dresden, Germany, 2015.
- Thomas Grill and Jan Schlüter: Music Boundary Detection Using Neural Networks on Spectrograms and Self-Similarity Lag Matrices. In Proceedings of the 23rd European Signal Processing Conference (EUSIPCO 2015), Nice, France, 2015.
- Bernhard Lehner, Gerhard Widmer, and Sebastian Böck: A Low-latency, Real-time-capable Singing Voice Detection Method with LSTM Recurrent Neural Networks. In Proceedings of the 23rd European Signal Processing Conference (EUSIPCO 2015), Nice, France, 2015.
- Karen Ullrich, Jan Schlüter, and Thomas Grill: Boundary Detection in Music Structure Analysis using Convolutional Neural Networks. In Proceedings of the 15th International Society for Music Information Retrieval Conference (ISMIR 2014), Taipei, Taiwan, 2014.
- Bernhard Lehner, Gerhard Widmer, and Reinhard Sonnleitner: On the Reduction of False Positives in Singing Voice Detection. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2014), Florence, Italy, 2014.
- Jan Schlüter and Sebastian Böck: Improved Musical Onset Detection with Convolutional Neural Networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2014), Florence, Italy, 2014.
- Jan Schlüter and Sebastian Böck: Musical Onset Detection with Convolutional Neural Networks. In 6th International Workshop on Machine Learning and Music (MML) in conjunction with the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD), Prague, Czech Republic, 2013.
- Bernhard Lehner, Reinhard Sonnleitner, and Gerhard Widmer: Towards Light-weight, Real-time-capable Singing Voice Detection. In Proceedings of the 14th International Society for Music Information Retrieval Conference (ISMIR 2013), Curitiba, Brazil, 2013.
- Jan Schlüter: Learning Binary Codes for Efficient Large-Scale Music Similarity Search. In Proceedings of the 14th International Society for Music Information Retrieval Conference (ISMIR 2013), Curitiba, Brazil, 2013.
Additional sponsoring
We gratefully acknowledge the support of NVIDIA Corporation with the donation of a Tesla K40 GPU used for this research.
Gallery
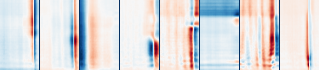
We learned spectro-temporal features for independently detecting the presence of speech in radio broadcasts.
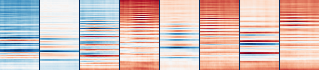
We learned spectro-temporal features for independently detecting the presence of music in radio broadcasts.
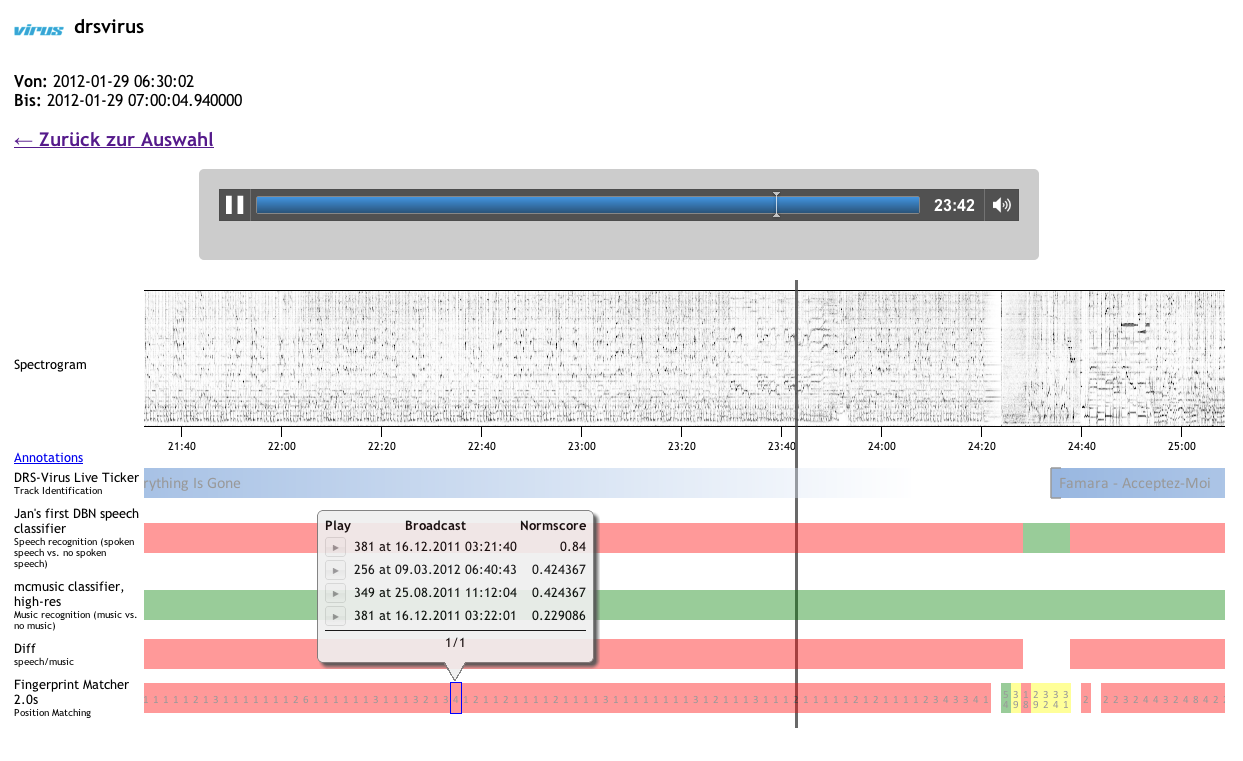
We developed a prototypical web-based tool to visualise and compare different annotations or segmentations by humans or our algorithms.

We developed and licensed a software component for segmenting radio broadcasts to the Danish company RadioAnalyzer.
Research staff
- Arthur Flexer
- Sebastian Böck
- Jan Schlüter
- Thomas Grill
- Karen Ullrich
- Gerhard Widmer
Sponsors

Translational Research – № TRP 307-N23

Austrian Federal Ministry for Transport, Innovation and Technology (BMVIT)
Translational Research
- Duration
2013 to 2016 - Coordinator
OFAI - Sponsors
Austrian Science Fund
Austrian Federal Ministry for Transport, Innovation and Technology
- Contact
Arthur Flexer